接下来我们继续看排序题单的下一道—— P2676 [USACO07DEC]Bookshelf B👇
题目描述

这道题目也是一样的,我们要透过题目所给的生活情境,直接看到它的本质所在——给定一个长度为N的正整数数列,里面的数字为乱序排列,问最少几个数加和所得到的值能够大于等于B
既然把题目理清了,那么我们来想一下如何用代码进行实现。首先它要输入数列的长度N和那个标准数B,那我们就对应定义两个int型变量分别为n,b;
在输入数列数据的时候,长度为n的数组a[n]、for循环以及for循环里面的变量i自然也少不了;
除此以外,我们要对数组的元素加和后才能判断是否大于等于给定的正整数B;
最后我们要输出的是进行加和数字的最小个数,那么毋庸置疑我们还要定义一个计数器j进行计数。
那要实现进行加和的数字个数最少,那就要从大到小进行加和。那有个问题就横亘在我们眼前了——如何对一串无序的数组进行排序,使其以从大到小的格式储存起来?
排序方法介绍
排序的方法有很多种,其中比较常用的有冒泡排序、选择排序、插入排序、希尔排序、归并排序、快速排序、计数排序、堆排序、桶排序、基数排序这几种(还有其他常用的也欢迎大家来补充啦),就像上一道题目车厢重组使用的其实就是冒泡排序的方法。
快速排序(Quick Sort)
今天呢着重给大家介绍一下快速排序这种方法,首先说冒泡排序大家都是了解的,就是从数组左侧开始两两比较相邻的数字,如果右侧的数字小于左侧的数字则交换两个数字的位置,如此循环一直到n-1轮时我们仅需要比较最左侧的两个数字就可以得到排序后由小到大排列的数组。反之如果要得到由大到小的数组我们只要将高亮的的“小于”改成“大于”就好了。
下面一段引自【算法】排序算法之快速排序 - 知乎 (zhihu.com)
而快速排序则是对于冒泡排序的一种优化,增加了分治策略而得到的一种高效排序算法。快速排序使用分治策略就是把一个序列分为两个子序列。
① 从数列中挑出一个元素,称为 “基准”(pivot),
② 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
③ 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
递归到最底部时,数列的大小是零或一,也就是已经排序好了。这个算法一定会结束,因为在每次的迭代(iteration)中,它至少会把一个元素摆到它最后的位置去。
图解
用一张维基百科的动图大家可能更加清晰地了解什么是快速排序以及它是如何实现的👇
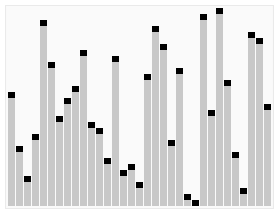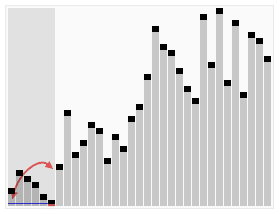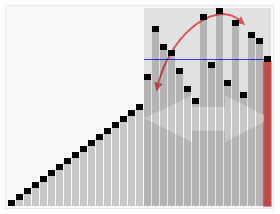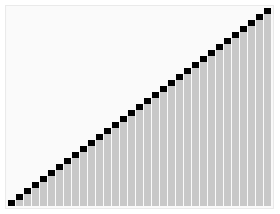
为何选择快排
这道题目在理论上使用冒泡排序也能够实现对数组的排序,但是为什么我们要使用快排而非冒泡呢?
是因为快排的时间复杂度为O(nlogn),而冒泡的的时间复杂度为O(n^2),再转眼一看,N的数据范围为(1≤N≤20,000)
那n^2已经是4*10^8,那这样的数据已经很大了,使用冒泡排序会极大的影响咱们的程序运行速率,导致超时无法AC
最后,我们使用手打快排也是可以的,但是那样会耗费大量的做题时间,比赛的时候也会拖慢我们的做题效率,故此我们大多数时候会直接使用c++STL标准库函数里面的sort(a,a+n,cmp),它对应的头文件是#include<algorithm>,或者当然啦,万能头文件也是可以的啦。
sort函数参数的意义
接下来我们来看看a、a+n以及cmp分别代表什么:
a是你要进行排序的数组的第一个元素的指针;
a+n是你要进行排序的数组的最后一个元素的下一个位置的指针;
cmp则是排序准则; 其中cmp不写的话计算机默认是从小到大进行排序,或者写less <int>()也是从小到大排序。如果我们要实现从大到小的排序,那我们就要写greater<int>(),当然如果要对double型的数据进行排序,我们就要在<>里面写double了。
至于其他的排序准则,后面我们会用到,今天就不在这里进行赘述了。
C++代码
所以这道题可以开始上AC代码啦👇
#include <bits/stdc++.h> //万能头文件
using namespace std;
int main()
{int n,b,i,j=0,sum=0; //定义相关变量cin >> n >> b ;int a[n];for(i=0;i<n;i++){cin >> a[i] ;}sort(a,a+n,greater<int>()); //对数据进行排序do{sum+=a[j];j++;}while(sum<b); //用do-while循环逐步求和cout << j ; //输出计数器的值就为最终答案return 0;
}希望我今天讲的对大家有所帮助,如果可以的话,能否点个免费的赞支持一下博主,谢谢大家啦~~

![P1884 [USACO12FEB]Overplanting S——洛谷](https://img-blog.csdnimg.cn/20200815181754376.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FubmFiZWxfQ00=,size_16,color_FFFFFF,t_70#pic_center)