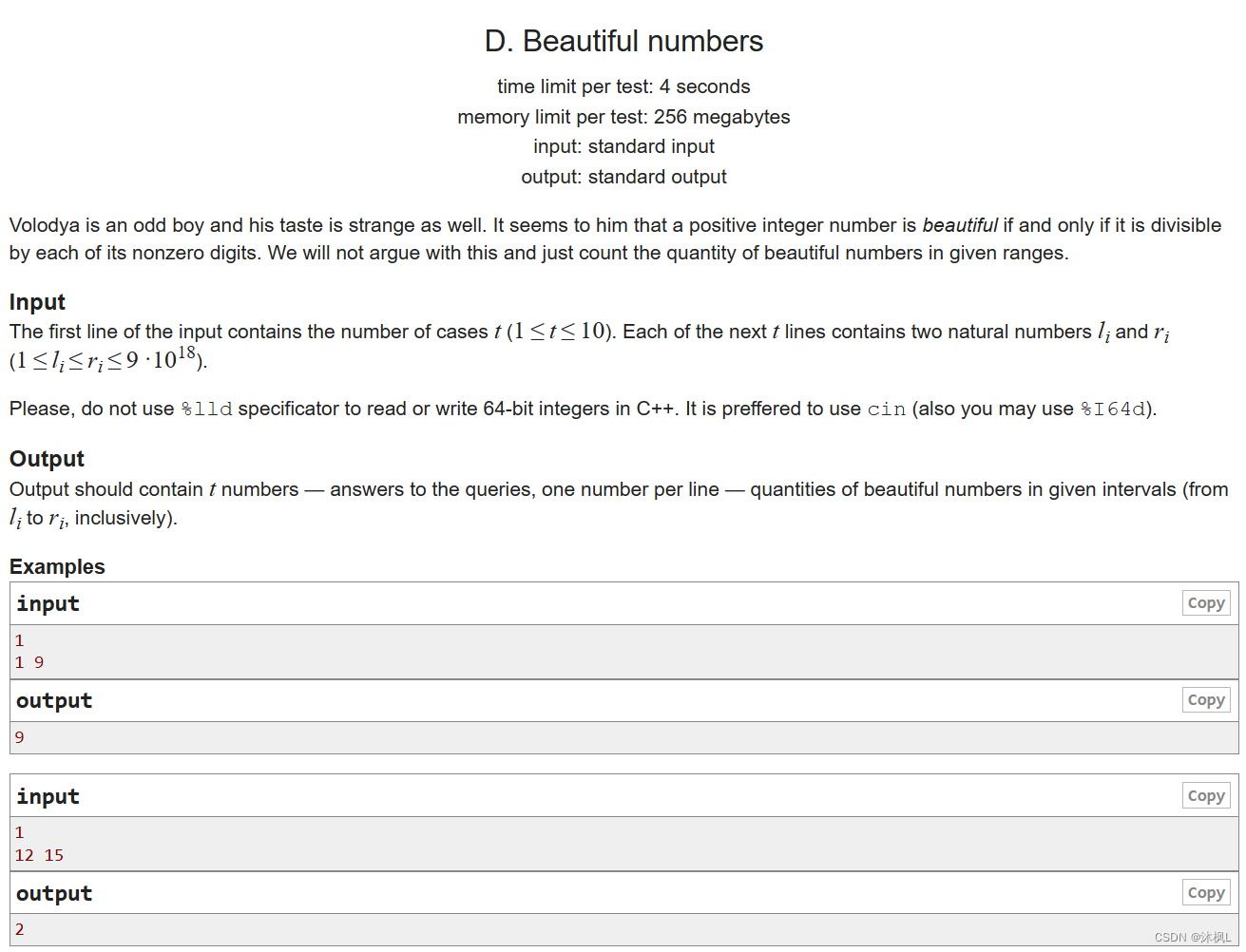
ChatGPT是OpenAI发布的基于GPT-3.5架构的大型语言模型,可用于各种自然语言处理任务,包括文本生成、对话系统、文本分类等。本文将为读者提供一份ChatGPT调教教程,帮助读者了解如何训练自己的ChatGPT模型,以便更好地满足自己的需求。
1. 安装必要的软件和工具
在开始之前,您需要安装一些必要的软件和工具。首先,您需要安装Python 3.x以及pip包管理器。然后,您需要安装Hugging Face Transformers库,它是用于训练和使用预训练模型的Python库。您还需要安装PyTorch,这是一个深度学习框架,它为Transformers库提供后端支持。您可以在终端或命令提示符中使用以下命令来安装这些软件和工具:
pip install transformers
pip install torch
2. 收集数据
ChatGPT的训练数据是一个非常关键的部分。您需要准备一个足够大且具有多样性的对话数据集,以便训练出一个优秀的ChatGPT模型。您可以从各种来源获得对话数据集,例如公开的对话语料库、社交媒体数据、聊天记录等。您还可以使用Web爬虫从互联网上收集数据。
3. 数据预处理
在开始训练模型之前,您需要对收集的数据进行预处理。这通常包括以下步骤:
- 清理数据:删除无用的标记、修复拼写错误、删除冗余数据等。
- 分割对话:将对话数据拆分成单独的对话,每个对话由多个对话回合组成。
- 格式化数据:将数据转换为模型可以理解的格式,例如将对话转换为对话对或对话文本序列
4.训练模型
在准备好数据后,您可以使用Transformers库中的GPT2LMHeadModel类来训练ChatGPT模型。您需要将预处理的数据加载到模型中,并使用模型进行训练。以下是一个示例代码片段:
from transformers import GPT2LMHeadModel, GPT2Tokenizer
import torchtokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')data = load_data() # 加载预处理数据inputs = tokenizer.encode(data, return_tensors='pt')
outputs = model(inputs)loss = outputs.loss
loss.backward()optimizer = torch.optim.Adam(model.parameters())
optimizer.step()
在训练过程中,您需要调整许多超参数,例如学习率、批次大小、训练时长等。您还可以使用早停策略,以便在模型达到最优性能时停止训练,避免过拟合。
5. 评估模型性能
在完成训练后,您需要评估ChatGPT模型的性能。评估性能的一种方法是使用人类评估器来评估生成的文本是否自然和流畅。您还可以使用BLEU、ROUGE和Perplexity等指标来评估模型性能。以下是一个使用BLEU指标评估模型性能的示例代码:
from nltk.translate.bleu_score import sentence_bleureference = ["hello, how are you today?"]
generated = "hi, how are you doing?"bleu_score = sentence_bleu([reference], generated)
print(bleu_score)
6. 调教模型
如果评估发现ChatGPT模型的性能不够理想,您可以采取以下一些方法来改善模型性能:
- 改变训练数据:增加数据集大小、改变数据集分布等。
- 调整模型架构:添加更多层、增加层大小、调整学习率等。
- 增加训练时间:增加训练周期、调整批次大小等。
7. 使用模型
在完成训练后,您可以使用ChatGPT模型来生成文本或作为对话系统的一部分。以下是一个生成文本的示例代码:
from transformers import GPT2LMHeadModel, GPT2Tokenizertokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('path/to/model')prompt = "Hello, how are you today?"
encoded_prompt = tokenizer.encode(prompt, add_special_tokens=False, return_tensors='pt')generated = model.generate(encoded_prompt, max_length=50, do_sample=True)
decoded_generated = tokenizer.decode(generated[0], skip_special_tokens=True)print(decoded_generated)
您还可以使用ChatGPT模型作为对话系统的一部分,以便回答用户提出的问题或完成特定任务。这需要更多的工作,包括对话管理、意图识别等。
总结
本文提供了一个简单的ChatGPT调教教程,帮助读者了解如何训练自己的ChatGPT模型以满足自己的需求。虽然这只是一个简单的示例,但它可以为读者提供足够的信息和知识,以便他们可以进一步研究和发展更加复杂的ChatGPT模型。希望读者可以从这个教程中获得启示,并能够开发出优秀的ChatGPT应用程序。
![python Matplotlib绘图实现:中文宋体,英文新罗马(科研人必备);解决Font family [‘sans-serif‘] not found.](https://img-blog.csdnimg.cn/cba37657e3de4621b7afe7faac724e60.png)