本篇博文转载于https://www.cnblogs.com/1024incn/tag/CUDA/,仅用于学习。
Warp
逻辑上,所有thread是并行的,但是,从硬件的角度来说,实际上并不是所有的thread能够在同一时刻执行,接下来我们将解释有关warp的一些本质。
Warps and Thread Blocks
warp是SM的基本执行单元。一个warp包含32个并行thread,这32个thread执行于SMIT模式。也就是说所有thread执行同一条指令,并且每个thread会使用各自的data执行该指令。
block可以是一维二维或者三维的,但是,从硬件角度看,所有的thread都被组织成一维,每个thread都有个唯一的ID(ID的计算可以在之前的博文查看)。
每个block的warp数量可以由下面的公式计算获得:
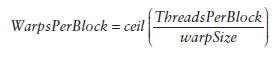
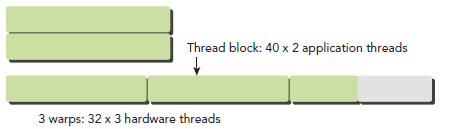
一个warp中的线程必然在同一个block中,如果block所含线程数目不是warp大小的整数倍,那么多出的那些thread所在的warp中,会剩余一些inactive的thread,也就是说,即使凑不够warp整数倍的thread,硬件也会为warp凑足,只不过那些thread是inactive状态,需要注意的是,即使这部分thread是inactive的,也会消耗SM资源。
Warp Divergence
控制流语句普遍存在于各种编程语言中,GPU支持传统的,C-style,显式控制流结构,例如if…else,for,while等等。
CPU有复杂的硬件设计可以很好的做分支预测,即预测应用程序会走哪个path。如果预测正确,那么CPU只会有很小的消耗。和CPU对比来说,GPU就没那么复杂的分支预测了(CPU和GPU这方面的差异的原因不是我们关心的,了解就好,我们关心的是由这差异引起的问题)。
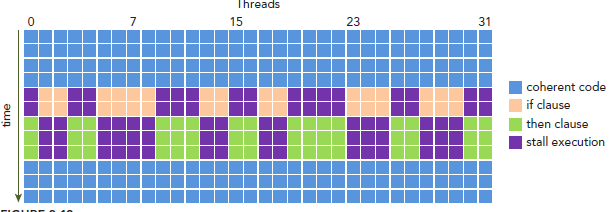
这样我们的问题就来了,因为所有同一个warp中的thread必须执行相同的指令,那么如果这些线程在遇到控制流语句时,如果进入不同的分支,那么同一时刻除了正在执行的分之外,其余分支都被阻塞了,十分影响性能。这类问题就是warp divergence。
请注意,warp divergence问题只会发生在同一个warp中。
下图展示了warp divergence问题:
为了获得最好的性能,就需要避免同一个warp存在不同的执行路径。避免该问题的方法很多,比如这样一个情形,假设有两个分支,分支的决定条件是thread的唯一ID的奇偶性:
__global__ void mathKernel1(float *c) {int tid = blockIdx.x * blockDim.x + threadIdx.x;float a, b;a = b = 0.0f;if (tid % 2 == 0) {a = 100.0f;} else {b = 200.0f;}c[tid] = a + b;
}一种方法是,将条件改为以warp大小为步调,然后取奇偶,如下:
__global__ void mathKernel2(void) {int tid = blockIdx.x * blockDim.x + threadIdx.x;float a, b;a = b = 0.0f;if ((tid / warpSize) % 2 == 0) {a = 100.0f;} else {b = 200.0f;}c[tid] = a + b;
}代码:
int main(int argc, char **argv) {
// set up device
int dev = 0;
cudaDeviceProp deviceProp;
cudaGetDeviceProperties(&deviceProp, dev);
printf("%s using Device %d: %s\n", argv[0],dev, deviceProp.name);
// set up data size
int size = 64;
int blocksize = 64;
if(argc > 1) blocksize = atoi(argv[1]);
if(argc > 2) size = atoi(argv[2]);
printf("Data size %d ", size);
// set up execution configuration
dim3 block (blocksize,1);
dim3 grid ((size+block.x-1)/block.x,1);
printf("Execution Configure (block %d grid %d)\n",block.x, grid.x);
// allocate gpu memory
float *d_C;
size_t nBytes = size * sizeof(float);
cudaMalloc((float**)&d_C, nBytes);
// run a warmup kernel to remove overhead
size_t iStart,iElaps;
cudaDeviceSynchronize();
iStart = seconds();
warmingup<<<grid, block>>> (d_C);
cudaDeviceSynchronize();
iElaps = seconds() - iStart;
printf("warmup <<< %4d %4d >>> elapsed %d sec \n",grid.x,block.x, iElaps );
// run kernel 1
iStart = seconds();
mathKernel1<<<grid, block>>>(d_C);
cudaDeviceSynchronize();
iElaps = seconds() - iStart;
printf("mathKernel1 <<< %4d %4d >>> elapsed %d sec \n",grid.x,block.x,iElaps );
// run kernel 3
iStart = seconds();
mathKernel2<<<grid, block>>>(d_C);
cudaDeviceSynchronize();
iElaps = seconds () - iStart;
printf("mathKernel2 <<< %4d %4d >>> elapsed %d sec \n",grid.x,block.x,iElaps );
// run kernel 3
iStart = seconds ();
mathKernel3<<<grid, block>>>(d_C);
cudaDeviceSynchronize();
iElaps = seconds () - iStart;
printf("mathKernel3 <<< %4d %4d >>> elapsed %d sec \n",grid.x,block.x,iElaps);
// run kernel 4
iStart = seconds ();
mathKernel4<<<grid, block>>>(d_C);
cudaDeviceSynchronize();
iElaps = seconds () - iStart;
printf("mathKernel4 <<< %4d %4d >>> elapsed %d sec \n",grid.x,block.x,iElaps);
// free gpu memory and reset divece
cudaFree(d_C);
cudaDeviceReset();
return EXIT_SUCCESS;
}编译运行:
$ nvcc -O3 -arch=sm_20 simpleDivergence.cu -o simpleDivergence $./simpleDivergence
输出:
$ ./simpleDivergence using Device 0: Tesla M2070 Data size 64 Execution Configuration (block 64 grid 1) Warmingup elapsed 0.000040 sec mathKernel1 elapsed 0.000016 sec mathKernel2 elapsed 0.000014 sec
我们也可以直接使用nvprof(之后会详细介绍)这个工具来度量性能:
$ nvprof --metrics branch_efficiency ./simpleDivergence
输出为:
Kernel: mathKernel1(void) 1 branch_efficiency Branch Efficiency 100.00% 100.00% 100.00% Kernel: mathKernel2(void) 1 branch_efficiency Branch Efficiency 100.00% 100.00% 100.00%
Branch Efficiency的定义如下:

到这里你应该在奇怪为什么二者表现相同呢,实际上当我们的代码很简单,可以被预测时,CUDA的编译器会自动帮助优化我们的代码。稍微提一下GPU分支预测(理解的有点晕,不过了解下就好),这里,一个被称为预测变量的东西会被设置成1或者0,所有分支都会得到执行,但是只有预测值为1时,才会得到执行。当条件状态少于某一个阈值时,编译器会将一个分支指令替换为预测指令,因此,现在回到自动优化问题,一份较长的代码就会导致warp divergence了。
可以使用下面的命令强制编译器不优化(貌似不怎么管用):
$ nvcc -g -G -arch=sm_20 simpleDivergence.cu -o simpleDivergence
Resource Partitioning
一个warp的context包括以下三部分:
- Program counter
- Register
- Shared memory
再次重申,在同一个执行context中切换是没有消耗的,因为在整个warp的生命期内,SM处理的每个warp的执行context都是on-chip的。
每个SM有一个32位register集合放在register file中,还有固定数量的shared memory,这些资源都被thread瓜分了,由于资源是有限的,所以,如果thread比较多,那么每个thread占用资源就叫少,thread较少,占用资源就较多,这需要根据自己的要求作出一个平衡。
资源限制了驻留在SM中blcok的数量,不同的device,register和shared memory的数量也不同,就像之前介绍的Fermi和Kepler的差别。如果没有足够的资源,kernel的启动就会失败。
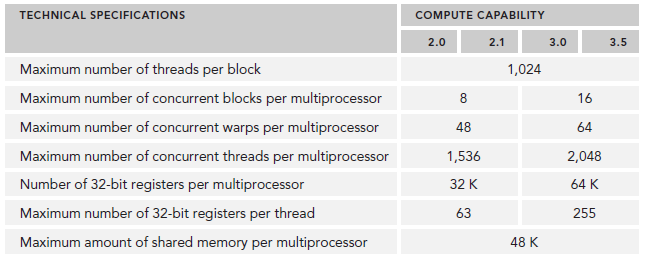
当一个block或得到足够的资源时,就成为active block。block中的warp就称为active warp。active warp又可以被分为下面三类:
- Selected warp
- Stalled warp
- Eligible warp
SM中warp调度器每个cycle会挑选active warp送去执行,一个被选中的warp称为selected warp,没被选中,但是已经做好准备被执行的称为Eligible warp,没准备好要执行的称为Stalled warp。warp适合执行需要满足下面两个条件:
- 32个CUDA core有空
- 所有当前指令的参数都准备就绪
CUDA编程中应该重视对计算资源的分配:这些资源限制了active warp的数量。因此,我们必须掌握硬件的一些限制,为了最大化GPU利用率,我们必须最大化active warp的数目。
Latency Hiding
指令从开始到结束消耗的clock cycle称为指令的latency。当每个cycle都有eligible warp被调度时,计算资源就会得到充分利用,基于此,我们就可以将每个指令的latency隐藏于issue其它warp的指令的过程中。
和CPU编程相比,latency hiding对GPU非常重要。CPU cores被设计成可以最小化一到两个thread的latency,但是GPU的thread数目可不是一个两个那么简单。
当涉及到指令latency时,指令可以被区分为下面两种:
- Arithmetic instruction
- Memory instruction
顾名思义,Arithmetic instruction latency是一个算数操作的始末间隔。另一个则是指load或store的始末间隔。二者的latency大约为:
- 10-20 cycle for arithmetic operations
- 400-800 cycles for global memory accesses
下图是一个简单的执行流程,当warp0阻塞时,执行其他的warp,当warp变为eligible时从新执行。
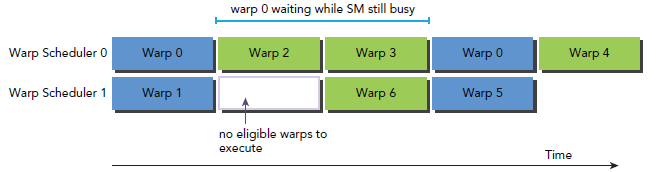
你可能想要知道怎样评估active warps 的数量来hide latency。Little’s Law可以提供一个合理的估计:
![]()
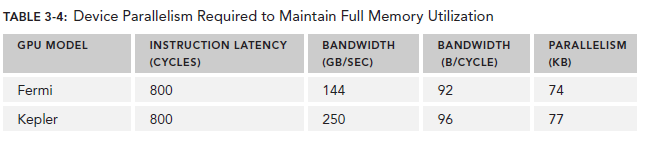
对于Arithmetic operations来说,并行性可以表达为用来hide Arithmetic latency的操作的数目。下表显示了Fermi和Kepler相关数据,这里是以(a + b * c)作为操作的例子。不同的算数指令,throughput(吞吐)也是不同的。

这里的throughput定义为每个SM每个cycle的操作数目。由于每个warp执行同一种指令,因此每个warp对应32个操作。所以,对于Fermi来说,每个SM需要640/32=20个warp来保持计算资源的充分利用。这也就意味着,arithmetic operations的并行性可以表达为操作的数目或者warp的数目。二者的关系也对应了两种方式来增加并行性:
- Instruction-level Parallelism(ILP):同一个thread中更多的独立指令
- Thread-level Parallelism (TLP):更多并发的eligible threads
对于Memory operations,并行性可以表达为每个cycle的byte数目。
因为memory throughput总是以GB/Sec为单位,我们需要先作相应的转化。可以通过下面的指令来查看device的memory frequency:
$ nvidia-smi -a -q -d CLOCK | fgrep -A 3 "Max Clocks" | fgrep "Memory"
以Fermi为例,其memory frequency可能是1.566GHz,Kepler的是1.6GHz。那么转化过程为:
![]()
乘上这个92可以得到上图中的74,这里的数字是针对整个device的,而不是每个SM。
有了这些数据,我们可以做一些计算了,以Fermi为例,假设每个thread的任务是将一个float(4 bytes)类型的数据从global memory移至SM用来计算,你应该需要大约18500个thread,也就是579个warp来隐藏所有的memory latency。

Fermi有16个SM,所以每个SM需要579/16=36个warp来隐藏memory latency。
Occupancy
当一个warp阻塞了,SM会执行另一个eligible warp。理想情况是,每时每刻到保证cores被占用。Occupancy就是每个SM的active warp占最大warp数目的比例:
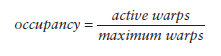
我们可以使用的device篇提到的方法来获取warp最大数目:
cudaError_t cudaGetDeviceProperties(struct cudaDeviceProp *prop, int device);
然后用maxThreadsPerMultiProcessor来获取具体数值。
grid和block的配置准则:
- 保证block中thrad数目是32的倍数。
- 避免block太小:每个blcok最少128或256个thread。
- 根据kernel需要的资源调整block。
- 保证block的数目远大于SM的数目。
- 多做实验来挖掘出最好的配置。
Occupancy专注于每个SM中可以并行的thread或者warp的数目。不管怎样,Occupancy不是唯一的性能指标,Occupancy达到当某个值是,再做优化就可能不在有效果了,还有许多其它的指标需要调节,我们会在之后的博文继续探讨。
Synchronize
同步是并行编程的一个普遍的问题。在CUDA的世界里,有两种方式实现同步:
- System-level:等待所有host和device的工作完成
- Block-level:等待device中block的所有thread执行到某个点
因为CUDA API和host代码是异步的,cudaDeviceSynchronize可以用来停住CUP等待CUDA中的操作完成:
cudaError_t cudaDeviceSynchronize(void);
因为block中的thread执行顺序不定,CUDA提供了一个function来同步block中的thread。
__device__ void __syncthreads(void);
当该函数被调用,block中的每个thread都会等待所有其他thread执行到某个点来实现同步。



![[每周一更]-(第68期):Excel常用函数及常用操作](https://img-blog.csdnimg.cn/045be5d78ee84b8d83514c0471f78607.png#pic_center)